Hack for Change
Hack for Change mapping project
4th June 2016 was Code For America’s “National Day of Civic Hacking” (or “Hack for Change” which is more speak-able). Tucson’s local event was held in the University of Arizona’s Science and Engineering library. The temperature in Tucson had just popped over 100F, that day in particular was forecast to be 113F, so there never was a better day for staying indoors hacking with plenty of air conditioning (and pizza).
Looking through the list of suggested projects I found the Opportunity Project particularly interesting because it involved taking advantage of federal+local open data for social good. It also gave the chance to investigate the CitySDK tool that works as a wrapper around the various APIs required to grab the different data sets available (census, FEMA, farmer’s markets, etc).
We formed at team of 3 (Jon Eckel, Pete Lowe and myself) called JustMapIt! (chosen to reflect our dedication to producing something by the end of the day). We decided that creating a visualisation that mapped the population income and/or poverty index across Tucson, along with access to grocery stores, may yield something interesting and useful. First we began by checking out the available data, making sure it contained data in the Tucson area!
The first major issue was that the CitySDK tool didn’t appear to be working. In the interest of time we decided to directly grab our own data sets instead.
Data sets
- INCOME IN THE PAST 12 MONTHS (IN 2014 INFLATION-ADJUSTED DOLLARS) from the 2014 American Community Survey 1-Year Estimates data for Arizona
- Latitude and Longitude positions of grocery stores in Tucson scraped from venues with categoryID=’Grocery Store’ in Foursquare using its API (and then cleaned a little)
In [40]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import folium
%matplotlib inlineThe income data
This data set gives the number of households and median income per census tract. Census tracts are small-ish, subdivisions of a county (or similar). Theys provide a stable set of geographic units for the presentation of statistical census data. Generally they contain a population size between 1,200 and 8,000 people, with an optimum size of 4,000 people.
In the data below the columns id and id2 contain the census tract id’s.
In [41]:
# household income census data
income_df = pd.read_csv("income_census_data.csv", header=[0,1], dtype={0:str, 1:str})Munging
There were two levels of column labels so the dataframe columns were multindexed. Since the upper level of labels gave no useful information, for ease of use we removed them.
In [42]:
# remove secondary column label
levels = income_df.columns.levels
labels = income_df.columns.labels
income_df.columns = levels[1][labels[1]]
# quick look at data
income_df.head()| Id | Id2 | Geography | Households; Estimate; Total | Households; Margin of Error; Total | Families; Estimate; Total | Families; Margin of Error; Total | Married-couple families; Estimate; Total | Married-couple families; Margin of Error; Total | Nonfamily households; Estimate; Total | ... | Nonfamily households; Estimate; PERCENT IMPUTED - Family income in the past 12 months | Nonfamily households; Margin of Error; PERCENT IMPUTED - Family income in the past 12 months | Households; Estimate; PERCENT IMPUTED - Nonfamily income in the past 12 months | Households; Margin of Error; PERCENT IMPUTED - Nonfamily income in the past 12 months | Families; Estimate; PERCENT IMPUTED - Nonfamily income in the past 12 months | Families; Margin of Error; PERCENT IMPUTED - Nonfamily income in the past 12 months | Married-couple families; Estimate; PERCENT IMPUTED - Nonfamily income in the past 12 months | Married-couple families; Margin of Error; PERCENT IMPUTED - Nonfamily income in the past 12 months | Nonfamily households; Estimate; PERCENT IMPUTED - Nonfamily income in the past 12 months | Nonfamily households; Margin of Error; PERCENT IMPUTED - Nonfamily income in the past 12 months | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1400000US04019000100 | 04019000100 | Census Tract 1, Pima County, Arizona | 319 | 50 | 48 | 38 | 34 | 31 | 271 | ... | (X) | (X) | (X) | (X) | (X) | (X) | (X) | (X) | 13.7 | (X) |
| 1 | 1400000US04019000200 | 04019000200 | Census Tract 2, Pima County, Arizona | 1916 | 189 | 914 | 182 | 452 | 145 | 1002 | ... | (X) | (X) | (X) | (X) | (X) | (X) | (X) | (X) | 26.7 | (X) |
| 2 | 1400000US04019000300 | 04019000300 | Census Tract 3, Pima County, Arizona | 680 | 86 | 244 | 54 | 109 | 54 | 436 | ... | (X) | (X) | (X) | (X) | (X) | (X) | (X) | (X) | 22.5 | (X) |
| 3 | 1400000US04019000400 | 04019000400 | Census Tract 4, Pima County, Arizona | 1719 | 97 | 395 | 101 | 253 | 78 | 1324 | ... | (X) | (X) | (X) | (X) | (X) | (X) | (X) | (X) | 27.5 | (X) |
| 4 | 1400000US04019000500 | 04019000500 | Census Tract 5, Pima County, Arizona | 1544 | 119 | 309 | 98 | 158 | 64 | 1235 | ... | (X) | (X) | (X) | (X) | (X) | (X) | (X) | (X) | 30.8 | (X) |
5 rows × 131 columns
In [43]:
print "Name of columns with income data:"
for col in income_df.columns:
if "income" in col:
print colName of columns with income data:
Households; Estimate; Median income (dollars)
Households; Margin of Error; Median income (dollars)
Families; Estimate; Median income (dollars)
Families; Margin of Error; Median income (dollars)
Married-couple families; Estimate; Median income (dollars)
Married-couple families; Margin of Error; Median income (dollars)
Nonfamily households; Estimate; Median income (dollars)
Nonfamily households; Margin of Error; Median income (dollars)
Households; Estimate; Mean income (dollars)
Households; Margin of Error; Mean income (dollars)
Families; Estimate; Mean income (dollars)
Families; Margin of Error; Mean income (dollars)
Married-couple families; Estimate; Mean income (dollars)
Married-couple families; Margin of Error; Mean income (dollars)
Nonfamily households; Estimate; Mean income (dollars)
Nonfamily households; Margin of Error; Mean income (dollars)
Households; Estimate; PERCENT IMPUTED - Household income in the past 12 months
Households; Margin of Error; PERCENT IMPUTED - Household income in the past 12 months
Families; Estimate; PERCENT IMPUTED - Household income in the past 12 months
Families; Margin of Error; PERCENT IMPUTED - Household income in the past 12 months
Married-couple families; Estimate; PERCENT IMPUTED - Household income in the past 12 months
Married-couple families; Margin of Error; PERCENT IMPUTED - Household income in the past 12 months
Nonfamily households; Estimate; PERCENT IMPUTED - Household income in the past 12 months
Nonfamily households; Margin of Error; PERCENT IMPUTED - Household income in the past 12 months
Households; Estimate; PERCENT IMPUTED - Family income in the past 12 months
Households; Margin of Error; PERCENT IMPUTED - Family income in the past 12 months
Families; Estimate; PERCENT IMPUTED - Family income in the past 12 months
Families; Margin of Error; PERCENT IMPUTED - Family income in the past 12 months
Married-couple families; Estimate; PERCENT IMPUTED - Family income in the past 12 months
Married-couple families; Margin of Error; PERCENT IMPUTED - Family income in the past 12 months
Nonfamily households; Estimate; PERCENT IMPUTED - Family income in the past 12 months
Nonfamily households; Margin of Error; PERCENT IMPUTED - Family income in the past 12 months
Households; Estimate; PERCENT IMPUTED - Nonfamily income in the past 12 months
Households; Margin of Error; PERCENT IMPUTED - Nonfamily income in the past 12 months
Families; Estimate; PERCENT IMPUTED - Nonfamily income in the past 12 months
Families; Margin of Error; PERCENT IMPUTED - Nonfamily income in the past 12 months
Married-couple families; Estimate; PERCENT IMPUTED - Nonfamily income in the past 12 months
Married-couple families; Margin of Error; PERCENT IMPUTED - Nonfamily income in the past 12 months
Nonfamily households; Estimate; PERCENT IMPUTED - Nonfamily income in the past 12 months
Nonfamily households; Margin of Error; PERCENT IMPUTED - Nonfamily income in the past 12 months
It seems the column we want to look at is “Households; Estimate; Median income (dollars)”
In [44]:
median_income = income_df["Households; Estimate; Median income (dollars)"]
print median_income.describe()
print median_income[:30]
#fig = plt.figure(figsize=(10,10))
#ax = fig.add_subplot(111)
#ax.hist(median_income)
#fig = plt.figure(figsize=(10,10))
#ax = fig.add_subplot(111)
#ax.hist(median_income)count 241
unique 240
top 27472
freq 2
Name: Households; Estimate; Median income (dollars), dtype: object
0 24861
1 24856
2 30739
3 18792
4 23188
5 51667
6 25805
7 44250
8 34492
9 39145
10 26983
11 30441
12 13193
13 22955
14 14940
15 21599
16 27573
17 50387
18 41507
19 28874
20 33947
21 48258
22 33380
23 28247
24 32857
25 28084
26 23778
27 24214
28 29292
29 30878
Name: Households; Estimate; Median income (dollars), dtype: object
The output from describe looks odd though the data itself looks ok. Also an
error is raised on trying to plot it, with hist
TypeError: len() of unsized object
or with plot
ValueError: could not convert string to float:
In [45]:
# check by eye
#for val in median_income:
# print val, type(val)
# Sample output:
# 84410 <type 'str'>
# 65284 <type 'str'>
# 53460 <type 'str'>
# 39798 <type 'str'>
# - <type 'str'>
# 29923 <type 'str'>
# 27664 <type 'str'>
# 34726 <type 'str'>
# 34000 <type 'str'>
# print all entries with "-" for Households; Estimate; Median income (dollars)
for index, row in income_df.iterrows():
if row["Households; Estimate; Median income (dollars)"]=='-':
print "Median income =", row["Households; Estimate; Median income (dollars)"],
print "Number of households =", row["Households; Estimate; Total"]Median income = - Number of households = 0
There is one entry where there is a null value (-) for the median income, and
this corresponds to a census tract with 0 households (this seems to be because
this tract is a State Prison complex).
So we need to ignore the tract where number of households=0, and also convert
the data to floats (because its type is string).
In [46]:
median_income = income_df.ix[(income_df["Households; Estimate; Total"] > 0),
"Households; Estimate; Median income (dollars)"].astype(float)
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(111)
ax.hist(median_income, 50)
ax.set_xlabel('median income in AZ per tract ($)', fontsize=24)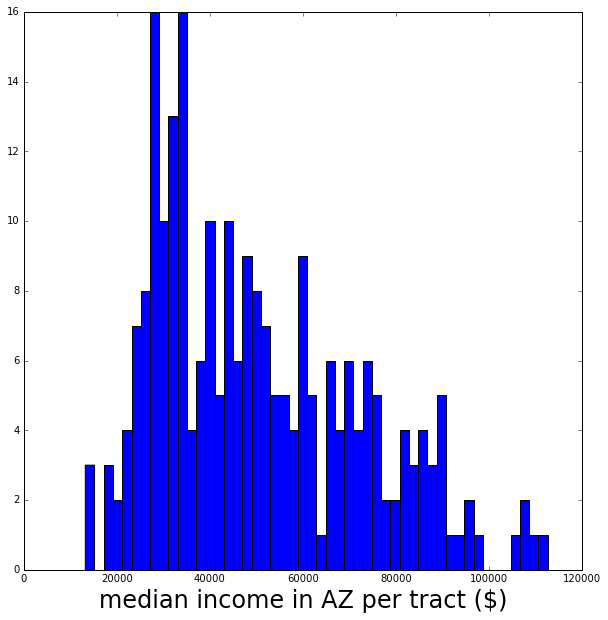
Read in the Tucson grocery store data
Scraped from foursquare into a simple CSV file
In [47]:
supermarkets = pd.read_csv("grocery_stores.csv")
supermarkets.head()| lat | lon | name | addr | |
|---|---|---|---|---|
| 0 | 32.229253 | -110.873651 | Kimpo Market | 5595 E 5th St |
| 1 | 32.220195 | -110.807966 | Walmart Neighborhood Market | 8640 E Broadway Blvd |
| 2 | 32.118384 | -110.798278 | Safeway | 9050 E Valencia Rd |
| 3 | 32.256930 | -110.943687 | India Dukaan | 2754 N Campbell Ave |
| 4 | 32.193137 | -110.841855 | Walmart Neighborhood Market | 2550 S Kolb Rd |
Folium for mapping
Folium is a python wrapper for the Leaflet javascript library, which itself can render interactive maps.
We need a way to convert the census tract ID to its equivalent area on the map, the census website provides this data in the form of ESRI Shapefiles.
Folium works with GeoJSON files so we need to convert. Handily we can do this using an online converter
In [48]:
import folium
import json
# GeoJSON file of Arizona census tracts
state_geo = "arizona.json"
# initialize map
tucson_coords = [32.2,-110.94]
mp = folium.Map(location=tucson_coords, zoom_start=11)
# map data to geo_json
mp.geo_json(geo_path=state_geo,
data=income_df.ix[(income_df["Households; Estimate; Total"] > 0)],
data_out="median_income.json",
columns=["Id2", "Households; Estimate; Median income (dollars)"],
key_on="feature.properties.GEOID",
fill_color='YlGn',
fill_opacity=0.7,
line_opacity=0.2 ,
threshold_scale= np.logspace(np.log10(15000), np.log10(125000), 6).tolist(),
legend_name='Median Income')
# plot the supermarkets on the map
for i,row in supermarkets.iterrows():
name = row["name"].decode("utf8")
mp.circle_marker(location=[str(row["lat"]), str(row["lon"])], popup=name, radius=100, fill_color="red", )
# generate the HTML/Javascript
mp.create_map(path='tucson.html', plugin_data_out=False)Map!
Here is a link to the map. Unfortunately we ran out of time before being able to add a toggle to toggle between median income and another dataset (e.g. population density). This particular visualisation would also be served better by higher resolution income data than that given by census tracts, but it was a great start: we learned a lot and finished something!